
news
Series 2. Pipeline for Machine Learning
IVWorks combines epitaxy technology with artificial intelligence (AI) to provide differentiated, high-quality Epi wafer foundry services. Three articles are presented in this series in which we divide semiconductor manufacturing and AI series into data, model, and platform, respectively. Let us explore the appearance of a semiconductor from the perspective of a researcher directly involved in DOMM AI Epitaxy System research.
Containerization has enabled developers to distribute software quickly and efficiently and achieve an unprecedented level of scalability. With an increase in the number of clouds used in enterprises, it has become difficult to set up containers for each device, and solutions to manage the containers located on multiple nodes have emerged. A representative solution is Kubernetes of Google. The need for Kubernetes and containers has been covered sufficiently in the previous column. If you have not seen it yet, I recommend reading it.
Platforms such as Kubernetes provide the basis for various application software to function. However, it is entirely up to the development team to develop and maintain application software that operates on these platforms. In the case of machine-learning services, a series of processes is followed iteratively while working on a project. This is called a pipeline.
In literatures and artificial intelligence (AI) competitions, such as those hosted by Kaggle, the evaluation is based on metrics, such as the model accuracy or f-score. Articles often say, “Since the index is improved by a certain amount compared with the existing model, it opens a new horizon,” and in a Kaggle competition, the model with the highest score in the index wins the first place. It may appear that model development accounts for most of the overall system development.
However, projects that aim to commercialize a model invest most of the time to analyze data or to train and tune the developed model iteratively rather than to develop the model. Even after a model is developed, a machine-learning system used in a real production environment is far more complex than imagined, with several technologies applied. Hence, all these processes need to be managed (that is, through pipelines).
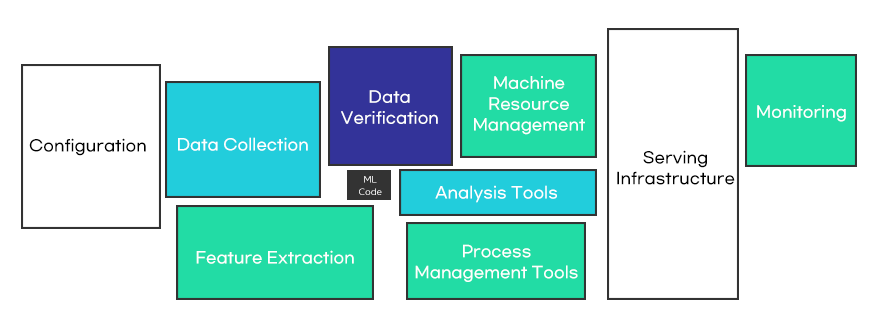
The figure below is a simplified representation of the machine-learning pipeline to help readers understand better. In practice, each step is very complex, and sometimes, the work is repeated until the developer is satisfied. In the middle of a project, model evaluation or monitoring may be conducted repeatedly from the beginning or middle of the pipeline. In other words, developing (building and training) a model is only a part of the pipeline.
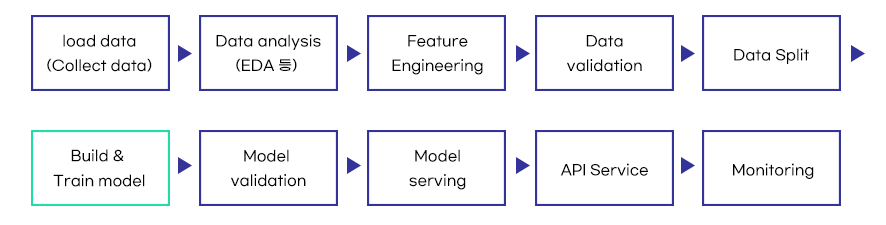
For a successful project, the machine-learning pipeline needs to be efficiently managed. Therefore, the pipeline needs to be automated to make it as easy to manage as possible. Automation reduces the administrative burden of simple, repetitive tasks, thereby allowing more time for relatively more important tasks, such as data analysis or model building and training. If a data scientist who builds and trains the model could be seen as a resource, automation lays the foundation for him or her to focus on model building and training.
Building a solid pipeline is closely associated with the competitiveness of a company. Machine-learning training and inference often requires expensive hardware, such as a graphics processing unit (GPU). The pipeline enables the efficient use of the hardware to reduce the model development costs. Pipeline management tools include Apache Airflow and Amazon SageMaker Pipeline. Kubernetes mentioned earlier uses Kubeflow. IVWorks distributes and uses various management tools according to the purpose in order to build a robust pipeline with a minimal cost for creating a platform in the compound semiconductor field. As for the cloud, IVWorks is building a pipeline with Kubeflow and Amazon SageMaker, and on-premises, Apache Airflow, which supports collaboration among numerous workers, is used.
Kubeflow orchestrates complex workflows to manage machine-learning pipelines. The dashboard, Jupyter labs, frameworks for training, Hypertune, pipelines, and tools for model inference facilitate the building of machine-learning pipelines.
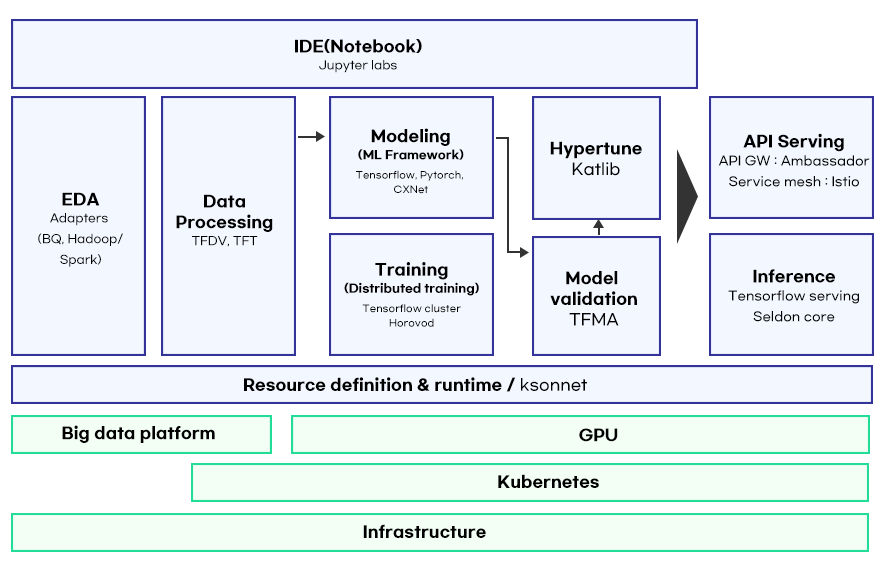
Used by tens of thousands of companies, including 3M, AstraZeneca, Domino’s, and Bayer, Amazon SageMaker is a service built based on 20 years of experience of Amazon in developing real-world machine-learning applications. SageMaker provides a continuous integration and deployment (CI/CD) service built specifically for machine learning for easy pipeline building. Last year, new features were updated to help automate and extend every step of the machine in workflow, such as improved transparency, distributed learning capabilities, and model monitoring on edge devices.

Each pipeline management tool has advantages and disadvantages. Airflow has a relatively long history, and it can be easily installed and operated on-premises. SageMaker boasts easy operation as a fully managed service, and it can quickly access the AWS infrastructure to create any pipeline imaginable. However, its dependence on AWS and its rather expensive fee are disadvantages. Finally, Kubeflow of Kubernetes does not have a long history, but it has all the essential elements that can be combined to create a pipeline. It is not dependent on AWS, and it uses Kubernetes infrastructure as it runs based on Kubernetes. The only limitation is that it is a separate pipeline from SageMaker. However, the development of technologies to connect SageMaker with Kubeflow or Kubernetes has enabled the creation of a pipeline by utilizing the two management tools.
IVWorks plans to build an optimal pipeline by combining Kubeflow and SageMaker in the future. Accordingly, IVWorks will provide a system optimized for recipe development, such as a machine-learning prediction model required for compound semiconductor growth as well as a growth analysis report and a real-time monitoring dashboard.
Jun-Suk Chang l Artificial Intelligence team
Reference
- 쿠버네티스 기반의 End2End 머신러닝 플랫폼 Kubeflow #1 – 소개[웹사이트]. (2019.1.9).
- Kubeflow 소개[웹사이트]. (2020.3.4).
- Kubeflow – Kubeflow Pipelines 이해하기[웹사이트]. (2020.3.8).
- 머신러닝 파이프라인이란? – ML Pipeline에 대하여[웹사이트]. (2020.3.29).
- Kubeflow, Wikipeida[웹사이트]. (2021.3.26).
- D. Sculley, Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Dietmar Ebner, Vinay Chaudhary, Michael Young, Jean-François Crespo, Dan Dennison, “Hidden Technical Debt in Machine Learning Systems”, NIPS(2015), p4-5
- 인공지능신문 – AWS, ‘세이지메이커’ 러닝머신 구현에 9가지 새 기능으로 더 편리하고 똑똑해졌다 (2020.12.12).