
news
DIVA, an Artificial Intelligence Model Development Methodology for Successful AI Model Development

DIVA, the optimal AI model development methodology designed by IVWorks
Do you have your own life route? As a human, you may encounter difficulties or follow an unexpected direction owing to the absence of a defined way or order of living. Hence, you may expect these things:
“It will be wonderful if there is a smooth and quick route to success from the beginning!”
“How many more mistakes will I make? I hope to meet someone who knows when I should stop and tells me to do so!”
The development of artificial intelligence (AI) is similar to the process of designing a life. AI researchers and developers seek the most convenient, fastest, and optimal route to perform AI development successfully beyond obstacles, systematize AI algorithms, and provide desirable AI services. However, AI development requires the participation of numerous people from a few to hundreds of people to achieve these goals.
Under these circumstances, IVWorks proposed DIVA, a new system that can derive optimal work efficiency for AI development. DIVA presents necessary procedures for developing and systematizing AI models and providing AI services based on the developed models. This system also introduces methods that enable users to achieve optimal efficiency for AI research and development. Although AI model research has been conducted in various fields, few institutions or companies have established their own procedures for systematizing AI model development methods considering the supply of AI services. DIVA is the optimal AI model development route that we created through countless trials and errors. This system has been widely applied in practical AI research tasks. We truly hope that our stories can provide support for those who are willing to conduct research and experiments on AI models, systematize these models, and supply AI-based services. In the following text, we will describe DIVA, the AI development methodology of IVWorks.
Necessity of Flexible and Systematic Connection between AI Model Development and Systematization

Data and Modeling
model research apply various methods to their repeated AI model research and experiments in research environments mainly based on Jupyter, specific kernel environments, etc. This significantly delays the swift systematization of AI models.
esources of GPU(graphics processing units). The application of the same model in both experimental and production environments is also difficult. Thus, the following conditions should be ensured to enable AI model researchers and developers to achieve AI model systematization effectively and conveniently:
• A standardized system that has registered a dataset developed by IVWorks or can newly register and manage such a dataset
• A standardized system that facilitates repeated experiments on an AI model under the same conditions, and registers and manages the corresponding model
• Efficient research and experimental environment considering systematization

Platform
Machine learning engineers, who are responsible for systematization, should also consider various aspects. For example, they are concerned about how to establish a stable on-premise environment that derives the optimal performance of a microservice architecture and what types of AI-based services should be provided on each platform.
In addition, they should perform their tasks by reflecting service flexibility and scalability, limited resources (particularly those for a system at the edge level), interface-related techniques, and AI model management measures. Furthermore, they should precisely recognize diverse versions of AI models and the dependency between packages in the process of implementing AI models. If AI model researchers develop and experiment with an AI model in their individual and unorganized environment in the modeling process and deliver a relevant source code to machine learning engineers, the process of systematizing the AI model on a specific platform can become a new project.
Consequently, the aforementioned processes induce considerable conflicts between modeling and platform divisions, cause these divisions to suffer from stress, and delay the time for providing a developed AI model as a service to users. The following items should be considered to provide a developed AI model as a service on a platform:
• An architecture that can flexibly apply deployment and management regardless of on-premise or cloud environment
• A system where an appropriate framework and packages for an AI model are optimized, installed, and stably operated
• A stable, swift, and flexible structure for using an AI model and connecting relevant services
• A system that can smoothly monitor the performance of an AI model
Six Stage of DIVA, an AI model development methodology
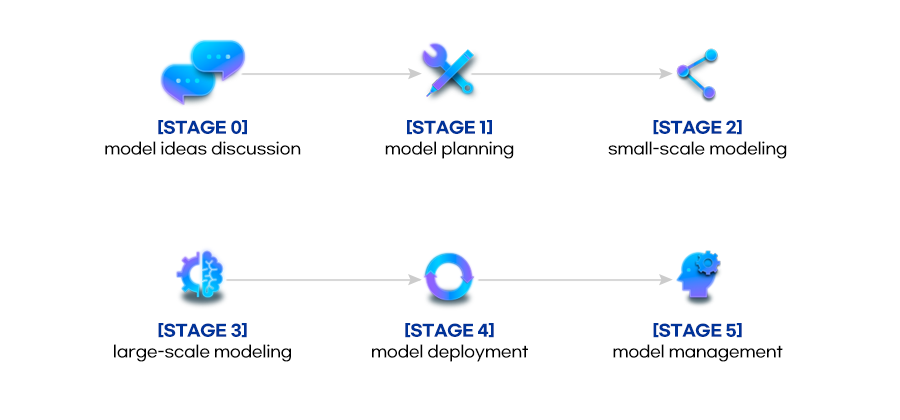
Six stages of DIVA, an AI model development methodology ⓒ IVWorks
DIVA consists of six stages from Stage 0 to Stage 5, and each stage includes milestones that should be achieved to complete certain procedures or derive specific outcomes. When users pass a milestone at the completion of each stage, they need to decide if they will proceed to the next stage or repeat the current stage based on a limited cycle. This process procedurally prevents redundant tasks and unnecessary time consumption, and enables users to focus on essential goals.
The following section briefly describes the stages of DIVA in order.
[STAGE 0] Model ideas discussion
• In this stage, users create ideas on practically valuable AI models and exchange their ideas and opinions with other people freely and simply.
• When users agree that a proposed idea has clear goals and can bring considerable expected effect, they will proceed to the next stage.
• If a specific idea has already been discussed and registered, users can omit this stage and directly proceed to Stage 1.
☑ Main checkpoints
✓ Analyze if the intention of planning and expected effect are clear.
✓ Examine if a proposed model has practical value from the perspectives of researchers and users.
✓ Identify types of input and output data.
[STAGE 1] Model Planning
• In this stage, users plan and design model research and development.
☑ Main checkpoints
✓ Analyze if the intention of planning and expected effect are clear and if a proposed model has practical value from the perspectives of researchers and users.
✓ Identify types of input and output data.
✓ Confirm if a research plan is specific.
✓ Examine if a target dataset is an existing dataset. If so, decide on a specific version of this dataset to be used.
✓ Verify techniques and research papers that were referred to as references.

ⓒ IVWorks
[STAGE 2] Small-scale modeling
• In this stage, users conduct small-scale modeling and experiments quickly to verify the proper operation of the designed model.
• If model planning was clearly completed in the previous stage, small-scale modeling can be conducted.
• Users can perform experiments in a comparatively flexible research environment.
☑ Main checkpoints
✓ Users can newly create a small dataset and register it in a standardized dataset registry system (DVC, data version control).
✓ Users should register information regarding an experiment on the designed model in a standardized model management system (MLflow).
[STAGE 3] Large-scale modeling
• In this stage, users conduct an experiment on the designed model on a large scale.
• Large-scale modeling can be performed only when the potential of the designed model was verified in the previous stage.
• After this stage, the modeling research division assigns the systematization task to the platform division and returns to the first stage to conduct different research.
☑ Main checkpoints
✓ An experiment in this stage should be performed in an environment considering systematization.
✓ An experiment begins after the platform division is provided with IVWorks’ standardized Docker base images including framework and packages according to model types.
✓ Users can use a dataset registered in the standardized dataset registry system. They may need to expand a small dataset created in the previous stage and register the expanded dataset as a large dataset.
✓ Users should repeatedly register information regarding experiments on models designed in a standardized environment in the standardized model management system (MLflow) to compare the performance of the trained models.

ⓒ IVWorks
[STAGE 4] Model deployment
• In this stage, users apply a generated model to the DOMM platform.
• This stage begins only when the value of the designed model was verified in the previous stage.
☑ Main checkpoints
✓ An experiment in this stage should be performed in an environment considering systematization.
✓ A system based on Docker images, which were created in a standardized environment and provided to users, is established and registered in a standardized Docker image repository.
✓ The trained model is deployed in the production system as a version determined in a standardized model management system (MLflow).
✓ In this stage, users can connect the new production system with relevant systems (DOMM Inference, DOMM Workflow, DOMM Watch, etc.) to the DOMM platform to provide services according to the service type of the trained model.
[STAGE 5] Model management
• In this stage, users can maintain and control the performance of the model registered on the DOMM platform.
☑ Main checkpoints
✓ Users should regularly monitor the performance of the trained model.
✓ The performance of the model of the production version should be compared with that of the model of a different version in the monitoring process.
✓ The status of the production model should be managed.
Six Stage of DIVA practically applied in tasks
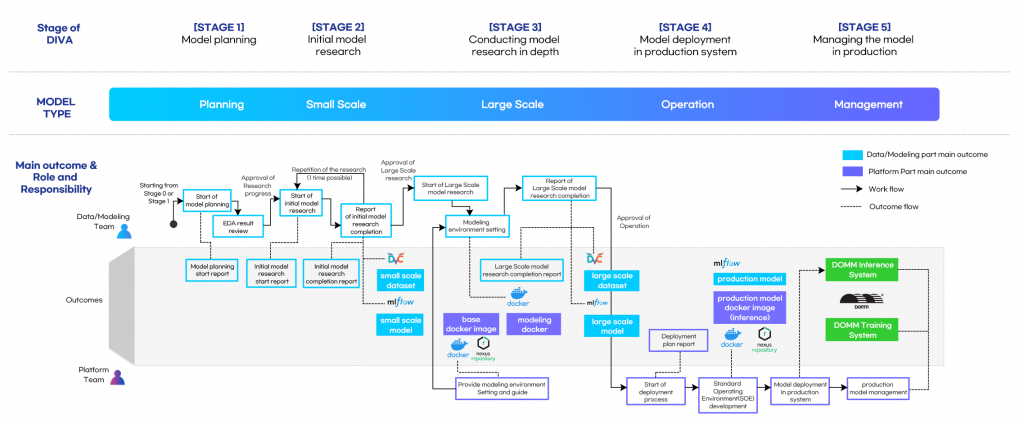
The overall flow of DIVA, the AI development method ⓒ IVWorks
IVWorks has defined the six stages of DIVA, our AI model development methodology, described above and applied these stages in practical tasks. Please refer to the figure shown above to view the overall flow of this system. Stage 0 (Model ideas discussion) was omitted from the figure shown above because users can discuss ideas without being bound by forms regardless of time.
In short, the users of DIVA can gain the following advantages:
• Standardized outcomes are accumulated on a specific schedule according to stages. When users conduct similar research or use similar data or environments later, they can save a considerable amount of time by avoiding unnecessary time consumption.
• Model researchers can efficiently conduct research and experiments. When model research is successfully completed, the systematization of a designed model is smoothly performed.
• Those responsible for platforms (machine learning engineers) can focus on deploying the optimal system based on a standardized system.
• DIVA enables users to conduct research and experiments efficiently on an outstanding model, deploy the trained model quickly, and provide services based on it.
In terms of AI model development, sustainable and systematic processes, which have apparent roles and responsibilities (R&R) in each stage and are appropriate for milestones for each stage, should be established to increase the efficiency of research and experiments effectively and derive outcomes. In the next story, we will discuss the technologies and systems that we applied to platforms internally. Thank you so much.
Hong-Kyun Noh ㅣ Artificial Intelligence Team leader & CIO at IVWorks
“We spread values of data”
【Terminology】
1) Development methodology: This system presents a summarized set of processes of software or system development to increase the quality and efficiency of development.
2) DIVA: This AI model development methodology developed by IVWorks presents a summarized set of processes from the development of an AI model to the systematization of the developed model.
3) DOMM: This machine learning platform developed by IVWorks provides functions for collecting and processing data on the developmental structure of an epitaxial layer, training a model, operating a prediction mode in real time, and creating an analysis report.
4) Small dataset: This dataset is used in experiments for quickly determining the direction of a designed model. The formulation of a dataset or version update is required for a model created from a new approach.
5) Large dataset: This dataset id used in large-scale experiments where real-world models can be operated.
6) Standardized dataset management system: This system performs the configuration management of datasets to facilitate the convenient use of these datasets during research. DVC is used as a standardized dataset management system.
7) Standardized model management system: This system manages the history of research and experiments on models and controls the operating and nonoperating versions of these models. MLflow is used as a standardized model management system. An exceptional model may exist as well.
8) Docker image: This image is a package of an operating system and the necessary environment and programs which are essential for this system.
9) Docker image repository: This is used to save Docker base images created by research and development processes in a standardized environment. Nexus Repository is used as a Docker image storage.
10) Docker base: These standardized Docker images consist of an AI framework, relevant packages, and installed IVWorks’ standardized packages. An appropriate image can be selected according to the model types and data used. Those responsible for modeling should perform model research and development based on Docker base images provided from Stage 3.
11) Data modeling: This process enables users to establish data and a model algorithm that matches the goals of model establishment and create a model through repeated experiments.
12) Servitization: This process enables users to deploy the trained model to a system and provide it as a service by adjusting its form to be more appropriate for the target system according to model types. The types of input and output data, time, model types registered in a system, and the location of an operating system may vary according to model types. There are services that run all the time, or services that only run when an event occurs.