
news
Series 2. machine learning for video analysis Embedding
IVWorks combines epitaxy technology with artificial intelligence (AI) to provide differentiated, high-quality Epi wafer foundry services. Three articles are presented in this series in which we divide semiconductor manufacturing and AI series into data, model, and platform, respectively. Let us explore the appearance of a semiconductor from the perspective of a researcher directly involved in DOMM AI Epitaxy System research.
The image analysis conducted in this study was covered in the previous model research column. The latest algorithms in image analysis have constantly been presented. Furthermore, higher performance than that obtained from the classification by the human eye has also been reached with these algorithms. However, the performance of the video analysis model is slightly behind that of the image analysis model, as the amount of data for training is not large when compared to that of the image analysis model, a significant amount of resources are required for training, and the flow of time or action is difficult to be recognized.
However, the recently presented algorithm has resulted in a good performance. The state-of-the-art (sota) performance is currently attributed to ACAR Net, which was presented by the University of Hong Kong at CVPR 2020 AVA-Kinetics Challenge and was further improved by using the SlowFast model developed by Facebook AI Research (FAIR) as a backbone. The SlowFast model also took the first place in the action area at the CVPR2019 AVA challenge.
SlowFast Network

The method to recognize action used by the SlowFast Network is similar to that used by the human eye. The design is divided into a slow pathway and fast pathway, which are respectively represented by the upper and lower parts of the figure above. The slow and fast pathways are trained by using low frame rates and real-time flow, respectively, at the same time. As a result, the slow pathway can recognize slowly changing information (color, texture, light, etc.), and the fast pathway can recognize the rapidly changing human action.

Video recognition algorithms are mainly action recognition models using kinetics data, which are composed of up to 650,000 large-scale, high-quality video clips provided by Deepmind, in which human behaviors are labeled. Furthermore, video analysis in various fields, such as the combination of multimodel data with manufacturing videos or audio, is still a difficult task.
IVWorks has also deeply investigated methods to analyze video data and has concluded that the embedding layer, which contains information that can better represent the semantics of the video, should be used rather than performing an analysis using the raw data of the video, as performed by the SlowFast model.
What is embedding
The concept of “word embedding” is any of a set of language modeling and feature learning techniques in natural language processing in which words or phrases of vocabulary are mapped to vectors of real numbers, therefore involving a mathematical embedding from a space with many dimensions per word to a continuous vector space of a much lower dimension. (Source: Wikipedia).
The term embedding is also used for images and videos when trying to represent information from high to low dimensions. The CNN that was covered in the previous section can learn many features by filtering and pooling the data. Subsequently, the data composed of all feature information flattened through a fully connected layer is mainly used for embedding.
A YouTube video was embedded by Google AI Perception during the Collaborative Deep Metric Learning for Video Understanding (2018). The author proposes an embedding network that can be applied to various domains , such as video classification, search, and personalized recommendations.
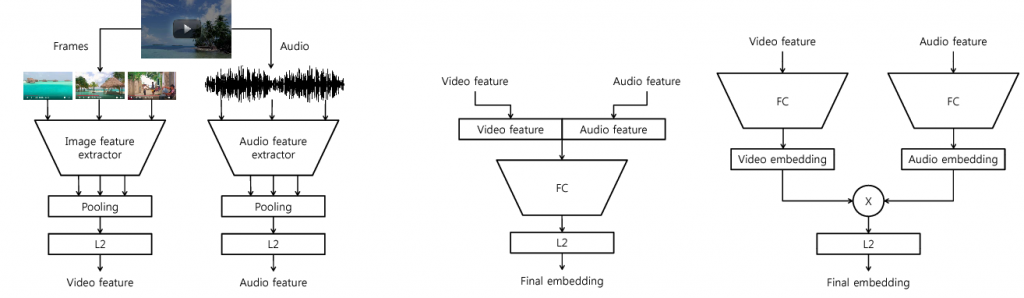
ⓒ Research paper for the collaborative deep metric learning for video understanding
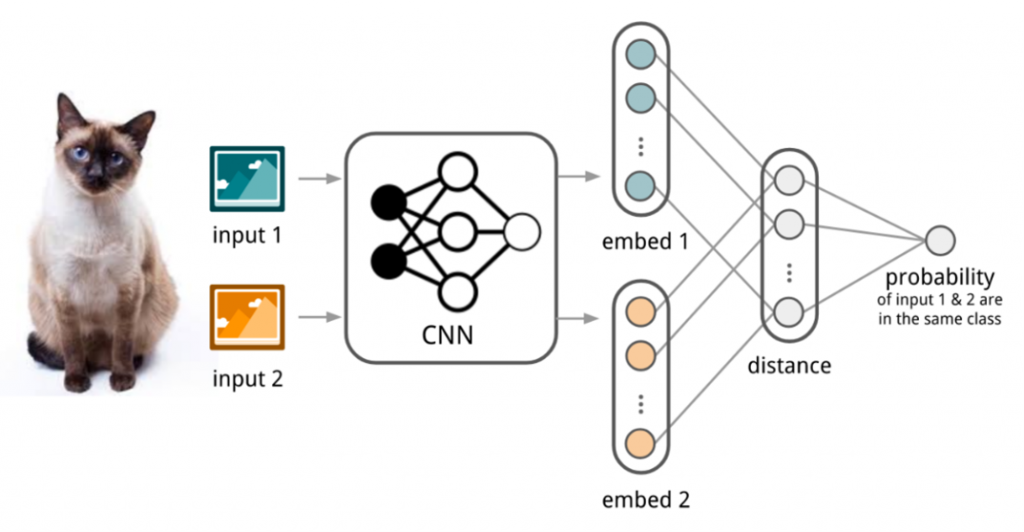
In Siamese networks, which were designed to distinguish inputs among many types of classes when the amount of images for a specific class is small, the term “embedding” was used to classify two different inputs through the distance from the two data using a feature extractor (CNN).
Video embedding of IVWorks
How does the video embedding of IVWorks work? The data we use are from a Rheed video. The growth process of the EPI wafer can be obtained from a Rheed video through MBE equipment. The change in the Rheed pattern was efficiently embedded with an algorithm combined with CNN. In addition, the index and information related to Rheed were quantified by our algorithm when trying to predict the quality evaluation index of the wafer. As a result, the performance of the video embedding algorithm was much higher than that of the video deep learning algorithm.
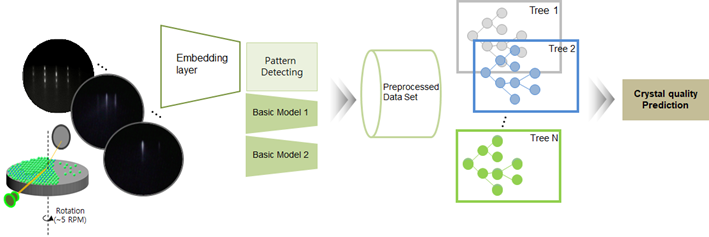
The model of IVWorks does not use the result of embedding the video alone. The performance of the crystal crystallinity prediction model developed by IVWorks was higher than 80% because it was combined with other basic models. Moreover, each feature became descriptive. The takeaway of the IVWorks AI team is that it is quite difficult to solve the problem with outstanding deep learning algorithms in an actual work environment; therefore, understanding and transforming the data to suit a purpose and applying machine learning models on the result can generate a much better solution.
However, IVWorks will not become complacent about the accuracy of 80%, as it is planning to further improve the performance of the model. The outstanding semiconductor material growth experts of IVWorks will cooperate with artificial intelligence experts to deeply understand the data, resulting in more robust models. The basic models of IVWorks and the method to improve the performance of the conventional models will be covered in the next article.
Seul-Lam KimㅣArtificial Intelligence team