
news

The code mentioned in the article is provided on colab for actual execution. colab link is https://colab.research.google.com/drive/1fB_or4_Xbxw-8Wl0psTd94ZyWRJ5XbFo?hl=ko#scrollTo=FZo_7MUlzbhD
What is a large language model (LLM)?
LLMs can perform various natural-language-processing tasks for specific texts, such as sentence generation, sentence classification, machine translation, question answering, and summarization. By learning from significant amounts of text data, these models can understand the meaning and grammatical structure of texts and then perform various natural-language-processing tasks based on the knowledge obtained.
The most commonly used LLMs include the GPT series, such as OpenAI’s ChatGPT 3.5 and Google’s BERT. These LLMs are pretrained on significant amounts of data and their performance on specific tasks can be improved via additional supervised learning.
Limitations of LLMs
First, LLMs can experience hallucinations. This refers to the model generating information that does not exist or misunderstanding the context for a specified input. For instance, it may not correct reveal the main character of a TV drama. This is referred to as hallucination.
Second, LLMs are not aware of the latest information. For example, at the time this article is written, ChatGPT 3.5 was trained only with data up to January 2022; therefore, it cannot reveal the current (as of March 2024) president of South Korea. Training LLMs is costly; therefore, they are trained at infrequent intervals, making it difficult to train them rapidly. thus resulting in limited information.
Finally, the sources used by LLMs to generate answers are unknown. Hence, to verify that validity of the generated answer, one must rely on their own basic knowledge or perform a separate search. If the source to an answer is provided, then users can immediately refer to the source to evaluate the credibility of the answer.
Several technologies to overcome limitations
· Retrieval augmented generation (RAG)
RAG is a technology used to reduce the aforementioned limitations of LLMs. Whereas the original ChatGPT can provide answers based on information available within the ChatGPT network, an LLM with RAG applied can provide answers based on information searched from the Internet or its own database. In other words, an LLM using RAG can refer to the documents provided when presenting an answer, similar to a cheat sheet. Whereas a basic LLM resembles a closed-book exam, an LLM using RAG resembles an open-book exam. Users can try out an LLM with RAG applied through Bing’s Copilot service.
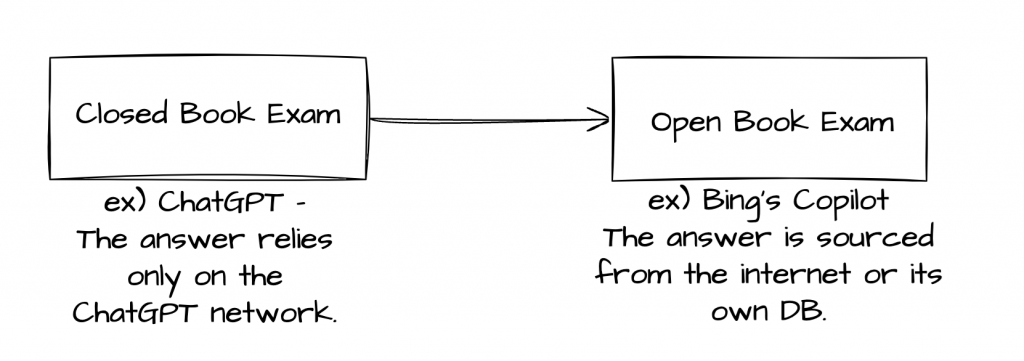
Ultimately, RAG serves as an AI framework that augments LLMs with accurate and updated information from external knowledge bases (the Internet or its own database) to provide users with enhanced insights. In essence, it is an AI framework that enables LLMs to be combined with external knowledge bases (the Internet or its own database). Herein, a “framework” refers to a software tool that provides a structural foundation to facilitate the rapid development and management of software.
· Fine-tuning
Fine-tuning is another technique to mitigate the limitations of LLMs. It entails the further adjustment of a pretrained LLM for a specific task or domain. LLMs are fundamentally models pretrained on significant amounts of text data, and fine-tuning customizes them further for specific tasks.
· Comparison between RAG and fine-tuning
RAG can directly utilize well-structured external data. However, because it must search for external data and then provide it to the LLM, a sophisticated search mechanism is necessary.
Fine-tuning achieves excellent performance in specific tasks. Fine-tuning a smaller model such as Llama-7b (7 billion parameters) for a specific task has been shown to yield better performance compared with fine-tuning larger models such as GPT-4 (1.76 trillion parameters).
However, fine-tuned models contain only data they were trained on; therefore, they are not aware of more recent information beyond their training. Additionally, the GPT series is only available via an API, which prevents it from being fine-tuned. Therefore, an openly available LLM such as Llama2 must be used for fine-tuning.
In conclusion, when creating an LLM service, one must select either RAG or fine-tuning based on the purpose of the service. If the latest information is important, then RAG would be advantageous; if performing a specific task, then fine-tuning would be more appropriate. Depending on the service, applying both RAG and fine-tuning simultaneously may be required.
Click here to read the full text of Creating an LLM service
IVWorks official Medium ‘Creating an LLM service for compound semiconductor manufacturing tasks’