
news

아이브이웍스가 고안한 최적의 인공지능 모델 개발 방법론 ‘DIVA’
여러분은 나만의 인생 루트가 설계되어 있나요? 인간에게는 정해진 삶의 방식이나 순서가 없어서 때론 어려움에 부딪히거나, 혹은 예상치 못한 방향을 걷기도 합니다. 그래서 가끔은 이런 생각을 합니다.
“처음부터 순탄하고도 빠른 길이 정해져 있으면 좋을 텐데!”
“이 실수를 몇 번이나 더 할까? 여기서 그만하라고 말해주는 사람이 있었으면!”
인공지능 개발은 인공지능의 인생을 만드는 것과 비슷합니다. 개발이 난관에 부딪히지 않게 가장 편리하면서도 빠른 최적의 루트로 ‘시스템화’와 ‘서비스’라는 목표에 도착하게 하지요. 하지만, 적게는 수 명에서 많게는 수백 명이 이 일에 달라붙다 보니 최적의 업무 효율성을 찾아헤매게 됐습니다.
여기서 ‘DIVA’가 활약합니다. 아이브이웍스의 ‘DIVA’는 인공지능 모델을 개발하고 시스템화하여 서비스하는 과정에서 필요한 주요 절차들과 최적의 연구개발 효율을 찾을 수 있는 방법을 다듬어 정리한 당사의 체계입니다. 인공지능 모델을 연구하는 곳은 많지만 개발 방법을 시스템화하여 서비스까지 고려한 절차를 가지고 있는 곳을 찾기란 힘듭니다. DIVA는 당사 연구팀의 많은 시행착오 끝에 마련된 최적의 인공지능 모델 개발 루트(route)로, 현재 아이브이웍스 인공지능 연구 실무에 활발히 적용되고 있습니다. 이 글이 인공지능 모델 연구부터 실험하고 시스템화하여 서비스하고자 고민하는 분들께 도움이 되길 바라며, 아이브이웍스의 인공지능 개발 방법론 ‘DIVA’에 대해 이야기해봅니다.
인공지능 모델 개발과 시스템화까지 ‘유연하고 체계적인 연결’이 필요해

데이터와 모델링
일반적으로 인공지능 모델을 연구한 전공자의 경우, 자신의 익숙한 환경에서 오픈된 데이터 셋으로 반복적인 모델 연구와 실험을 하는 경우가 많습니다. 반면, 기업에서는 이미 알려진 데이터 셋을 사용하지 않고, 새로운 모델 연구의 경우 데이터 셋부터 만들어야 하는 경우가 대부분입니다.
또, 인공지능 모델을 연구·실험할 때 본인의 연구환경 (Jupyter와 특정 커널 환경 등)에서 다양한 방법을 거쳐 반복적으로 모델을 연구하고 실험을 하는 경우가 많습니다. 하지만, 이 점은 향후 신속한 시스템화에 큰 지연 요소가 됩니다.
인공지능 모델 개발은 다른 SW 개발과 달리 프레임워크의 버전, 패키지들 간의 종속성 문제, GPU 자원의 문제 등 개발 환경이 시스템적으로 복잡한 편에 속합니다. 실험 환경과 운영환경에 동일한 모델을 적용하는 것은 생각보다 쉽지 않습니다. 따라서, 모델 연구자의 편의성과 효과적인 시스템화를 위해 다음과 같은 사항들이 필요합니다.
• 자사의 데이터 셋이 등록되어 있거나, 신규로 등록·관리할 수 있는 표준 체계
• 모델을 동일한 조건에서 반복 실험하고, 모델을 등록·관리하는 표준 체계
• 효율적이며 시스템화가 고려된 연구 실험 환경

플랫폼
시스템화를 담당하는 머신러닝 엔지니어 입장에서도 고려해야 할 것들이 많습니다. 클라우드, 온프레미스 환경에서 마이크로 서비스 아키텍처(MSA)가 최적의 성능으로 안정적인 환경을 구축해야 하고, 플랫폼에 서비스를 하려면 어떤 형태로 모델을 서비스할 것인가 등 생각할 것이 많습니다.
게다가 서비스의 유연함, 확장성, 제한적인 자원 (특히 Edge 단의 시스템) 등을 모두 고려해야 할 뿐더러, 인터페이스 방식이나 모델의 관리 방안도 생각해야 합니다.
특히, 인공지능 모델을 구현할 때는 모델별로 너무 다양한 버전과 패키지들의 의존성을 잘 알아야 합니다. 만약 모델링 단계에서 모델 연구자의 정리되어있지 않은 개인적 환경에서 개발 및 실험한 후 소스를 전달받았다면, 플랫폼에서 시스템화해야 하는 일은 완전히 새로운 프로젝트가 될 수도 있습니다.
결론적으로, 이는 모델링 조직과 플랫폼 조직에 상당한 마찰과 스트레스를 생기게 만들뿐더러 유저에게 모델을 서비스하는 시간도 지연되게 만듭니다. 플랫폼에서 모델을 서비스하는데 생각할 수 있는 주요 항목들은 다음과 같습니다.
• 온프레미스, 클라우드 환경에서 관계없이 배포와 관리를 유연하게 적용할 수 있는 아키텍처 구조
• 모델에 맞는 적합한 프레임워크와 패키지들이 최적화되어 설치되고 안정적으로 작동되는 시스템
• 모델 이용과 유관 서비스 연동에 안정적이고 빠르며 유연한 구조
• 모델의 성능 모니터링이 원활한 시스템
인공지능 모델 개발 방법론 DIVA 6단계
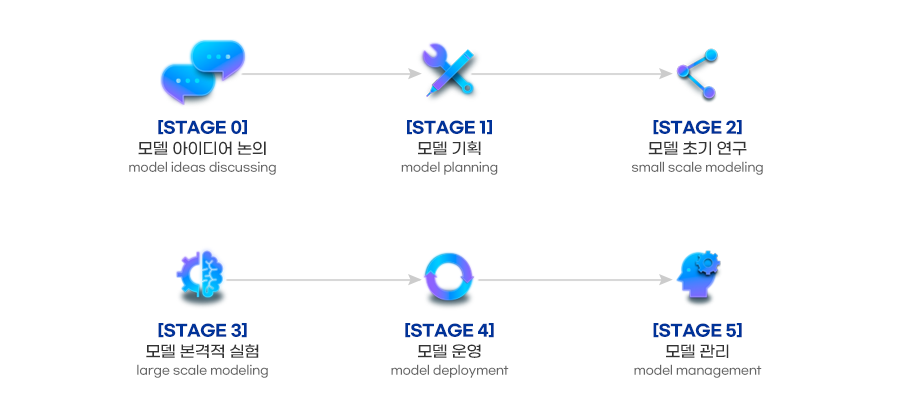
인공지능 모델 개발 방법론 DIVA 6단계 ⓒ 아이브이웍스 (IVWorks)
DIVA는 0단계부터 5단계까지 총 6단계로 이루어져 있으며, 각 단계에서는 주요 마일스톤을 두어 요구되는 절차나 산출물이 있습니다. 특히, 각 단계의 완료 단계의 마일스톤에서는 다음 단계로 연구를 진행할지 또는 해당 단계를 제한된 횟수만큼 반복할지 결정합니다. 이는 불필요한 중복 작업과 시간소모를 절차적으로 방지하고 본질적인 목표에 집중할 수 있도록 합니다.
여기서부터는 단계별 흐름 위주의 간략한 설명을 하겠습니다.
[STAGE 0] 모델 아이디어 논의 단계 (Model ideas discussing)
• 실질적 가치를 지닐 수 있는 모델을 생각해 보고, 자유롭게 간단하게 아이디어를 공유하여 의견을 교환하는 단계입니다.
• 논의 결과, 실체적 목표가 명확하고 기대효과가 높다고 판단될 경우 다음 단계로 진행됩니다.
• 이미 논의되어 등록된 아이디어의 경우, 해당 단계는 생략하고 1단계부터 바로 진행할 수 있습니다.
☑ 주요 체크 포인트
✓ 기획의도와 기대효과가 명확한가 확인합니다.
✓ 연구와 사용자 관점의 실질적 가치를 제시하고 있는지 확인합니다.
✓ Input 데이터 유형과 Output 데이터 유형을 확인합니다.
[STAGE 1] 모델 연구 개발 기획 단계 (Model Planning)
• 모델 연구 개발을 기획하고 설계하는 단계입니다.
☑ 주요 체크 포인트
✓ 기획의도와 기대효과가 명확한지, 연구자와 사용자 관점의 실질적 가치를 제시하고 있는지 확인합니다.
✓ Input 데이터 유형과 Output 데이터 유형을 확인합니다.
✓ 구체적인 연구계획이 확인되어야 합니다.
✓ 기존에 존재하는 데이터 셋인지, 그렇다면 어떤 버전을 사용할 계획인지 확인합니다.
✓ 레퍼런스로 참고한 기술과 논문은 어떤 것인지 확인합니다.

ⓒ 아이브이웍스 (IVWorks)
[STAGE 2] 모델 초기 연구단계 (Small-scale modeling)
• 설계한 모델이 작동할 것인지 신속하게 작은 범위의 모델링과 실험을 하는 단계입니다.
• 이전 단계에서 모델 계획이 명확한 경우 small scale modeling을 진행할 수 있습니다.
• 비교적 자유로운 연구 환경에서 실험할 수 있습니다.
☑ 주요 체크 포인트
✓ 데이터 셋을 신규로 만들어야 할 경우, small dataset으로 만들 수 있으며 데이터 셋 저장 표준체계(dvc)에 등록해야 합니다.
✓ 모델의 실험은 모델 관리 표준체계(mlflow)에 등록해야 합니다.
[STAGE 3] 모델(본격적) 연구 실험 단계 (Large-scale modeling)
• 설계한 모델을 보다 큰 규모로 실험하는 단계입니다.
• 이전 단계에서 모델의 가능성이 판단되었을 때, large scale modeling을 진행할 수 있습니다.
• 이 단계가 끝나면 모델링 연구조직은 플랫폼 조직으로 시스템화를 맡기고, 첫 단계로 돌아가서 다른 연구를 수행할 수 있습니다.
☑ 주요 체크 포인트
✓ An experiment in this stage should be performed in an environment considering systematization.
✓ 이 단계는 반드시 향후 시스템화가 고려된 환경에서 실험을 해야 합니다.
✓ 모델 유형에 따라서 플랫폼 조직에서 프레임워크와 패키지가 있는 자사의 표준 Docker base 이미지를 제공받은 후 실험이 시작됩니다.
✓ 데이터 셋 저장 표준체계에 등록된 데이터 셋을 사용합니다. 이전 단계의 small dataset을 확장하여 large dataset 등록이 필요할 수 있습니다.
✓ 실험하는 모델들은 표준 환경에서 계획된 실험을 모델 관리 표준체계 (mlflow)에 반복적으로 등록하여 성능 비교가 되어야 합니다.

ⓒ 아이브이웍스 (IVWorks)
[STAGE 4] 모델 운영 적용 단계 (Model deployment)
• 만들어진 모델을 DOMM 플랫폼에 적용하는 단계입니다.
• 이전 단계에서 모델의 가치가 충족되었을 때, 모델 운영 적용 단계가 진행됩니다.
☑ 주요 체크 포인트
✓ 이전 단계에서 이미 표준 환경 Docker base 이미지가 제공되었고, 표준 환경 위에 만들어진 Docker image를 기반으로 시스템이 빌드 되어 표준 도커이미지 저장소에 등록됩니다.
✓ 모델은 관리 표준체계(mlflow)에 지정된 버전으로 시스템에 반영됩니다.
✓ 모델의 서비스 형태에 맞게 서비스 되도록 DOMM 플랫폼의 유관 시스템 (DOMM Inference, DOMM Workflow, DOMM Watch 등)에 연동 작업을 진행합니다.
[STAGE 5] 모델 관리 단계 (Model management)
• DOMM에 등록된 모델의 성능을 유지·관리하는 단계입니다.
☑ 주요 체크 포인트
✓ Users should regularly monitor the performance of the trained model.
✓ 모델의 성능 모니터링을 주기적으로 진행합니다.
✓ 운영 버전과 다른 버전의 모델을 비교하여 모니터링할 수 있어야 합니다.
✓ 모델의 운영상태가 관리되어야 합니다.
실제 업무에 적용된 여섯 개의 DIVA Stages
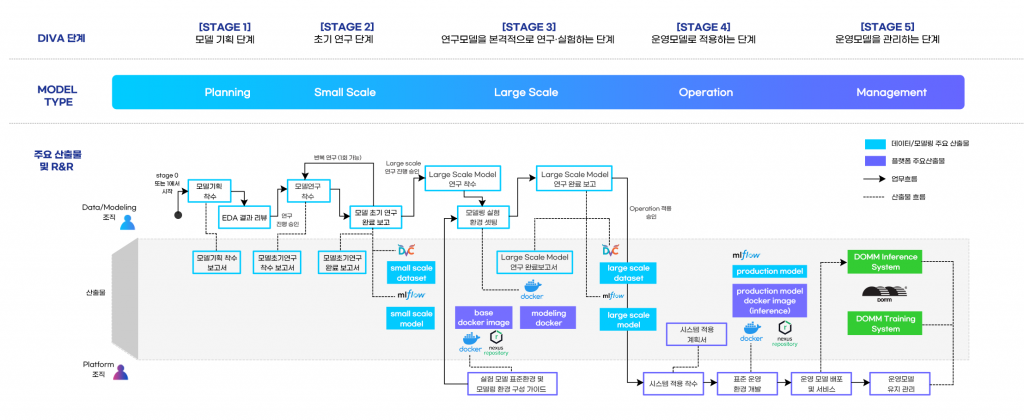
DIVA 인공지능 개발 방법론 전체 흐름 ⓒ 아이브이웍스 (IVWorks)
아이브이웍스에서는 인공지능 모델 개발 방법론 DIVA를 위의 6단계로 정의하여 업무에 적용하고 있습니다. 전체적인 흐름은 위 그림을 참고해주세요. 위 그림에서 아이디어 논의단계 STAGE 0이 제외된 이유는, 아이디어 논의는 형식에 얽매이지 않고 시간에 관계없이 언제든 일어나는 것이 맞기 때문입니다.
정리하자면, 인공지능 모델 개발 방법론(DIVA)를 사용하여 다음과 같은 장점을 가져갈 수 있었습니다.
• 단계별로 구체적인 일정하에 표준화된 산출물이 쌓이게 됩니다. 이후 유사한 연구, 데이터, 환경 을 사용할 때 불필요한 시간을 상당히 줄여줍니다.
• 모델 연구자는 연구와 실험을 효율적으로 할 수 있고, 모델의 연구가 성공적으로 끝났을 경우 자연스럽게 시스템화도 이루어집니다.
• 플랫폼 담당자(머신러닝 엔지니어)는 표준화된 시스템 체계에서 최적의 시스템 배포에 집중 할 수 있습니다.
• 결과적으로 좋은 모델을 효율적으로 연구 실험하고, 빠른 배포와 서비스가 가능해집니다.
인공지능 모델 개발에 있어서, 단계별로 R&R(Role and Responsibilities)이 명확하고 마일스톤에 맞는 지속적이고 체계화된 프로세스 구축은 연구 및 실험의 효용성 증대와 산출물 발생에 매우 효과적입니다. 다음 편에서는 아이브이웍스가 플랫폼 내부적으로 적용한 기술과 체계에 대해 이야기를 할 예정입니다. 감사합니다.
Hong Kyun Noh ㅣ Artificial Intelligence Team leader & CIO at IVWorks
“데이터에서 가치를 전달합니다”
【참고용어】
1) 개발 방법론 : 소프트웨어를 개발하거나 시스템을 만들때 그 과정들을 정리하여 개발의 품질과 효율성을 높이는 체계입니다.
2) DIVA : 아이브이웍스에서 만든 인공지능모델 개발방법론으로 인공지능 모델의 개발부터 시스템화까지의 과정이 정리되어 있습니다.
3) DOMM : 모든 에피층 성장구조 데이터의 수집, 가공, 모델 학습 및 예측 모델 실시간 운영, 분석리포트 기능을 구현한 자체 머신러닝 플랫폼입니다.
4) Small Dataset : 모델의 방향성을 빠르게 찾기 위한 수준의 실험에 사용되는 데이터셋입니다. 모델이 새로운 접근의 아이디어인경우 데이터셋을 만들거나, 버전 업데이트가 필요할 수 있습니다.
5) Large Dataset : 실제 모델을 운영할 수 있는 수준의 실험에 사용되는 데이터셋입니다.
6) 데이터셋 관리 표준체계 : 데이터셋을 형상관리하고, 연구시 쉽게 사용할수 있도록 관리하는 체계. dvc 를 표준으로 사용하고 있습니다.
7) 모델관리 표준체계 : 모델을 연구, 실험 이력 관리 및 버전, 운영버전 관리를 하는 표준 체계입니다. 표준으로 mlflow 를 사용하고 있습니다. 물론 예외모델도 존재할 수 있습니다.
8) 도커 이미지 : 시스템 운영체계와 필요한 환경과 프로그램을 셋팅하여 패키지 하여 묶어 놓은 것입니다.
9)도커이미지 저장소 : 표준환경 Docker Base와 연구개발하며 구성된 도커 이미지가 저장되는 공간입니다. nexus repository 를 사용하고 있습니다.
10) Docker base : 인공지능프레임워크, 연관된 패키지, 당사의 표준 패키지들이 설치된 표준화된 도커 이미지입니다. 모델유형, 사용하는 데이터등에 따라 적합한 이미지가 있습니다. 모델링 담당자는 STAGE 3 부터 반드시 제공되는 Docker base 이미지 기반으로 모델 연구와 개발을 진행해야 합니다.
11) 데이터, 모델링 : 모델의 목표에 맞는 데이터와 모델 알고리즘을 구상하고, 반복적인 실험으로 모델을 만드는 과정입니다.
12) 서비스화 : 모델의 유형에 따라 적합한 형태로 시스템에 배포하여 서비스하는 것입니다. 모델에 따라 입출력 데이터의 형태가 다르고 시점이 다르며, 시스템에 등록되는 형태와 동작하는 시스템의 위치가 다를 수 있습니다. 상시로 수행되어야하는 모델 이거나 이벤트가 발생하였을때 호출되는 형태가 있습니다.