
news
Series 2. 머신러닝을 위한 파이프라인(Pipeline)
아이브이웍스는 에피텍시 기술에 인공지능(AI)을 접목시켜 차별화된 고품질 에피웨이퍼 파운드리 서비스를 제공합니다. 본 연재에서는 반도체 제조와 AI 시리즈를 데이터, 모델, 플랫폼으로 나눠 각 세편에 걸쳐 발행합니다. DOMM AI Epitaxy System 연구에 직접 참여 중인 연구원 시각에서 전하는 화합물 반도체 제조는 어떤 모습일까요.
개발자들은 컨테이너화를 통해 신속하고 효율적인 소프트웨어 배포와 전례 없는 수준의 확장성을 확보할 수 있게 되었습니다. 기업에서는 클라우드 사용 개수가 늘어나면서 매번 장비별로 컨테이너를 설정하는 일이 어려워졌고, 여러 노드에 위치한 컨테이너들을 관리해 주는 솔루션이 등장하기에 이르렀습니다. 대표적으로 구글(google)의 쿠버네티스가 있지요. 쿠버네티스와 컨테이너의 필요성에 대해서는 지난 칼럼에서 충분히 다뤘으니, 아직 못 보셨다면 완독을 추천드립니다.
쿠버네티스와 같은 플랫폼들은 다양한 응용 소프트웨어가 작동할 수 있는 기반을 제공합니다. 하지만, 이런 기반에서 운용되는 응용 소프트웨어를 개발하고 서비스하는 것은 온전히 개발팀의 몫입니다. 머신러닝 서비스의 경우, 프로젝트를 진행하다 보면 반복적으로 겪는 일련의 과정이 있습니다. 이를 파이프라인(pipeline)이라고 합니다.
논문이나 캐글(kaggle)과 같은 인공지능(AI) 대회를 보면 모델의 정확도(accuracy) 혹은 F 점수(f-score)와 같은 지표(metric)를 기준으로 평가를 합니다. 논문에서는 ‘기존 모델보다 지표를 얼마만큼 향상시켰으므로 새로운 지평을 열었다’고 평가하고, 캐글에서는 지표 최고점을 기록하는 모델이 1등을 하는 식이죠. 이는 곧, 전체 시스템 개발 중에서 모델 개발이 대부분을 차지한다고 비칠 수 있습니다.
하지만, 모델을 실제로 제품화시켜야 하는 프로젝트에서는 모델 개발보다 데이터 분석이나 개발된 모델을 반복적으로 학습시키며 튜닝하는데 대부분의 시간을 소요합니다. 모델이 개발된 후에도, 실제 운영 환경에서 사용되는 머신러닝 시스템은 상상보다 훨씬 복잡하고 많은 기술이 적용됩니다. 그래서 이 모든 과정(파이프라인)을 관리하는 방법이 필요하게 됐습니다.
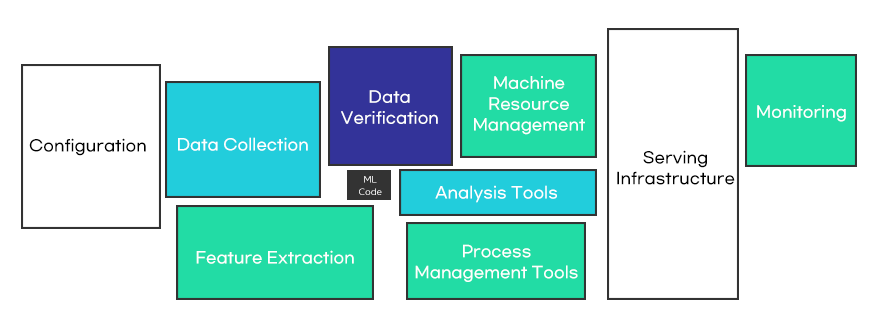
아래 그림은 독자들의 이해를 돕고자 머신러닝 파이프라인을 단순화시켜 표현한 것입니다. 실제로는 각 단계가 매우 복잡한 과정으로 이뤄지며, 개발자가 만족할 때까지 작업이 반복적으로 이뤄지기도 합니다. 프로젝트 중간에는 모델 평가나 모니터링을 통해 파이프라인의 처음이나 중간부터 반복적으로 진행하는 경우도 있습니다. 즉, 모델 개발(build&train model)은 파이프라인의 일 부분에 해당한다는 사실을 알 수 있습니다.
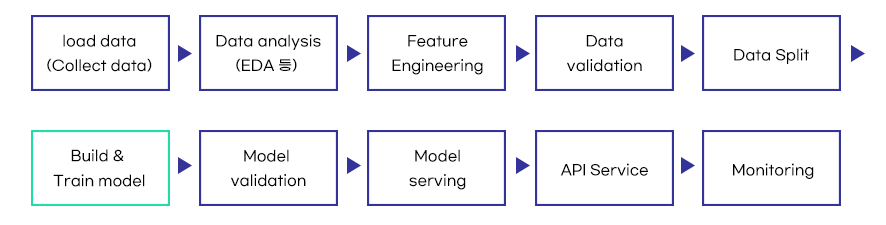
여기서도 마찬가지로 모델 개발은 시스템 개발의 일부분에 해당한다. (이미지 재구성)
프로젝트가 성공하기 위해서는 머신러닝 파이프라인을 효율적으로 관리할 필요가 있습니다. 그래서 파이프라인을 최대한 쉽게 관리할 수 있도록 자동화하는 것이 중요합니다. 자동화를 통해 반복되는 단순 업무에 대한 관리 부담을 줄이고, 상대적으로 중요한 데이터 분석 또는 모델 개발 및 훈련에 많은 시간을 할애할 수 있습니다. 즉, 모델을 개발하는 데이터 과학자도 자원(resource)로 본다면 모델 개발에 집중할 수 있는 기반을 마련해 주는 셈입니다.
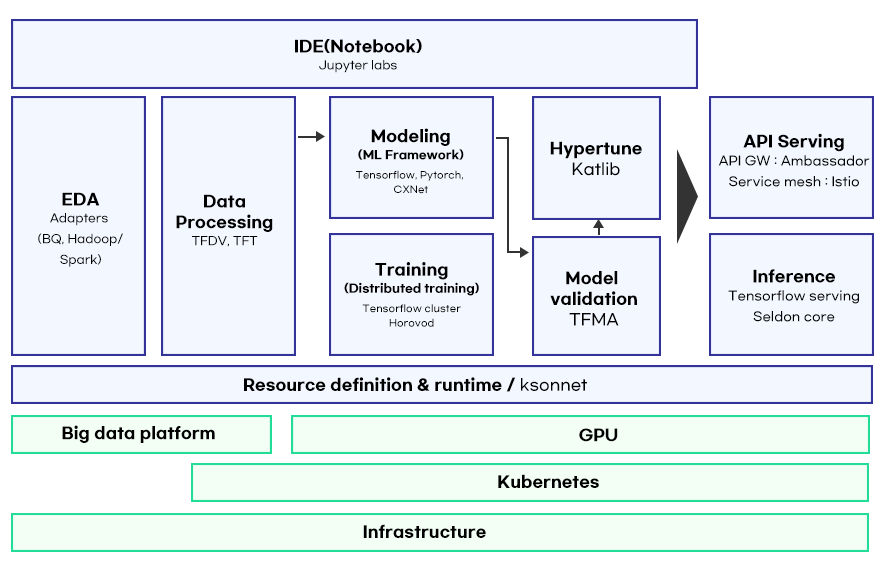
탄탄한 파이프라인 구축은 기업의 경쟁력과 직결됩니다. 머신러닝 학습 및 추론에는 GPU(graphics processing unit)처럼 고가의 하드웨어가 쓰이는 경우가 많습니다. 파이프라인은 하드웨어를 최대한 효율적으로 사용하여 모델의 개발 비용을 낮출 수 있습니다. 파이프라인 관리 툴에는 아파치 에어플로우(Apache Airflow), 아마존 세이지 메이커 파이프라인(Amazon SageMaker Pipeline) 등이 있습니다. 앞서 언급한 쿠버네티스의 경우, 쿠브플로우(Kubeflow)를 사용합니다. 아이브이웍스는 화합물 반도체 분야의 플랫폼을 만드는데 있어서 최소한의 비용으로 탄탄한 파이프라인을 구축하고자 다양한 관리 툴을 목적에 맞게 분배하여 사용합니다. 클라우드에서는 쿠브플로우와 아마존 세이지메이커로 파이프라인을 구축하고, 사내에서는 수많은 워커간의 협업을 지원하는 아파치 에어플로우를 사용하고 있습니다. 쿠브플로우는 복잡한 워크플로우를 조율하여 머신러닝 파이프라인을 관리해 줍니다. 대쉬보드, 주피터랩(Jupyter labs), 훈련(Training)을 위한 프레임워크, 하이퍼 파라미터 튜닝(Hypertune), 파이프라인, 모델 서빙(Inference)을 위한 툴 등을 사용하여 머신러닝 파이프라인을 손쉽게 구축할 수 있습니다.
3M, 아스트라제네카, 도미노피자, 바이어 등 수만 개 기업이 사용하는 아마존 세이지 메이커는 20년에 걸친 Amazon의 실제 머신러닝 학습 애플리케이션 개발 경험에 기반해 구축된 서비스입니다. 세이지 메이커는 머신러닝 학습을 위해 특별히 구축된 지속적이고 통합된 전달(CI/DC) 서비스를 제공하여 파이프라인을 손쉽게 구축할 수 있게 도와줍니다. 작년에는 투명성 향상, 분산 학습 기능, 엣지 장치에서의 모델 모니터링과 같이 머신러닝 워크플로우의 모든 단계를 자동화하고 확장할 수 있도록 새로운 기능들이 업데이트되기도 했습니다.

각각의 파이프라인 관리 툴은 장단점이 있습니다. 에어플로우는 상대적으로 오랜 역사를 갖고 있어서, 온프레미스에서 간편하게 설치하여 쉽게 운영할 수 있습니다. 세이지 메이커도 완전 관리형 서비스로 손쉽게 운영할 수 있고 AWS의 인프라에 빠르게 접근하여 상상 가능한 모든 파이프라인을 만들어낼 수 있습니다. 단, AWS에 종속된다는 점과 다소 비싼 요금은 단점입니다. 마지막으로, 쿠버네티스의 쿠브플로우는 개발 역사가 길지 않지만 필수 요소들은 모두 갖추고 있어서 각각의 요소들을 조합하여 파이프라인을 만들어낼 수 있습니다. AWS에 종속되지 않는다는 점과 쿠버네티스를 기반으로 동작하므로 쿠버네티스 인프라를 사용한다는 것도 장점입니다. 한계가 있다면 세이지 메이커와 독립된 별도의 파이프라인이라는 점입니다. 하지만, 세이지 메이커와 쿠브플로우 혹은 쿠버네티스를 연결할 수 있는 기술들이 개발되면서 두 가지 관리 툴의 장점을 살린 파이프라인을 만들 수 있게 되었습니다.
아이브이웍스는 향후 쿠브플로우와 세이지 메이커를 섞어서 최적의 파이프라인을 구축해나갈 예정입니다. 그를 토대로 화합물 반도체 성장에 필요한 머신러닝 예측 모델은 물론, 성장 분석 리포트와 실시간 모니터링 dashboard 등 레시피 개발에 최적화된 시스템을 제공해나갈 것입니다.
Jun-Suk Chang ㅣ Artificial Intelligence team
참고문헌
- 쿠버네티스 기반의 End2End 머신러닝 플랫폼 Kubeflow #1 – 소개[웹사이트]. (2019.1.9).
- Kubeflow 소개[웹사이트]. (2020.3.4).
- Kubeflow – Kubeflow Pipelines 이해하기[웹사이트]. (2020.3.8).
- 머신러닝 파이프라인이란? – ML Pipeline에 대하여[웹사이트]. (2020.3.29).
- Kubeflow, Wikipeida[웹사이트]. (2021.3.26).
- D. Sculley, Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Dietmar Ebner, Vinay Chaudhary, Michael Young, Jean-François Crespo, Dan Dennison, “Hidden Technical Debt in Machine Learning Systems”, NIPS(2015), p4-5
- 인공지능신문 – AWS, ‘세이지메이커’ 러닝머신 구현에 9가지 새 기능으로 더 편리하고 똑똑해졌다 (2020.12.12).