
news
Series 2. 영상분석을 위한 머신러닝 ‘임베딩(embedding)’
아이브이웍스는 에피텍시 기술에 인공지능(AI)을 접목시켜 차별화된 고품질 에피웨이퍼 파운드리 서비스를 제공합니다. 본 연재에서는 반도체 제조와 AI 시리즈를 데이터, 모델, 플랫폼으로 나눠 각 세편에 걸쳐 발행합니다. DOMM AI Epitaxy System 연구에 직접 참여 중인 연구원 시각에서 전하는 화합물 반도체 제조는 어떤 모습일까요.
지난 모델 탐구 칼럼에서는 이미지 분석에 관하여 살펴보았습니다. 이미지 분석의 최신 알고리즘은 끊임없이 발표되고 있고 성능 또한 개선됨으로 인해 인간의 눈으로 분류하는 수준보다 더 높은 성능에까지 이르렀습니다. 그러나 동영상 분석 모델은 이미지 분석 모델에 비해 성능이 다소 떨어집니다. 첫째, 훈련시킬 데이터의 양이 이미지에 비해 방대하지 않습니다. 둘째, 훈련시키는데 많은 자원이 듭니다. 셋째, 시간의 흐름이나 행동의 흐름을 인식하게 하는 것이 어렵습니다.
하지만 최근에 발표된 알고리즘은 좋은 성능을 이끌어냈는데, 현재 sota*의 성능으로는 CVPR 2020 AVA-Kinetics Challenge에서 홍콩대학교가 발표한 ACAR Net입니다. 이 알고리즘은 Facebook AI Research(FAIR)에서 만든 SlowFast 모델을 backbone으로 사용하여 좀 더 개선시킨 모델입니다. SlowFast 모델 역시 CVPR 2019 AVA challenge Action 분야에서 1등을 차지한 바 있습니다.
*State-of-the-art의 약자로 '현재 최고 수준'을 의미한다.
SlowFast Network

SlowFast Network에서는 사람의 시각과 비슷한 방법으로 행동을 인식하도록 설계되었습니다. 윗부분을 slow pathway, 아랫부분을 fast pathway라고 합니다. 동일한 시간에서 slow pathway는 frame 간격을 두고 학습시키고 fast pathway는 실시간 흐름을 학습시킵니다. 그렇게 되면 slow pathway는 느리게 변화하는 정보(색깔, 질감, 빛 등)를 인식하게 되고 fast pathway는 빠르게 변화하는 사람의 행동을 인식하게 됩니다.

그러나 영상인식(video recognition)의 알고리즘들은 주로 Kinetics의 데이터 (Deepmind에서 제공하는 데이터로 최대 650,000개 비디오 클립의 대규모 고품질 데이터로 사람의 행동이 라벨링 되어있다.)를 활용한 행동인식 모델로 제조 영상이나 오디오가 결합된 멀티 모달 데이터(Multimodel data) 등 여러 분야의 영상분석은 아직 어려운 과제입니다. 아이브이웍스 또한 영상 데이터를 어떻게 분석할지에 대한 고민이 깊었습니다. SlowFast 모델처럼 동영상 자체의 raw data를 가지고 분석을 하기보다, 영상의 의미를 잘 나타내줄 수 있는 정보가 담긴 embedding layer를 활용해야겠다는 결론에 도달하였습니다.
embedding(임베딩)이란
embedding이라는 표현을 검색해보면, ‘word embedding’이라는 개념이 먼저 나옵니다.
‘어휘의 단어나 구절이 실수 벡터에 매핑되는 자연어 처리의 언어 모델링 및 기능 학습 기술의 집합 중 하나다. 개념적으로 단어 당 많은 차원을 가진 공간에서 훨씬 더 낮은 차원을 가진 연속적인 벡터 공간으로의 수학적 임베딩을 포함한다.’ (위키백과)
이미지와 영상도 이와 같이 고차원에서 저차원으로 정보를 표현한다는 취지에서 ’embedding(임베딩)’이란 용어를 사용합니다. 지난 칼럼에서 살펴본 CNN은 filter와 pooling으로 많은 feature들을 학습합니다. 그리고 그 후에 fully connected layer를 통해 모든 feature의 정보들이 flatten된 데이터를 가지고 주로 임베딩으로 사용합니다.
실제로 구글 Google AI Perception에서 발표한 Collaborative Deep Metric Learning for Video Understading(2018)에서 유튜브의 영상을 임베딩하였습니다. 저자는 비디오 분류, 검색, 개인화된 추천 등 다양한 도메인을 다루기 위해 embedding network를 제안합니다.
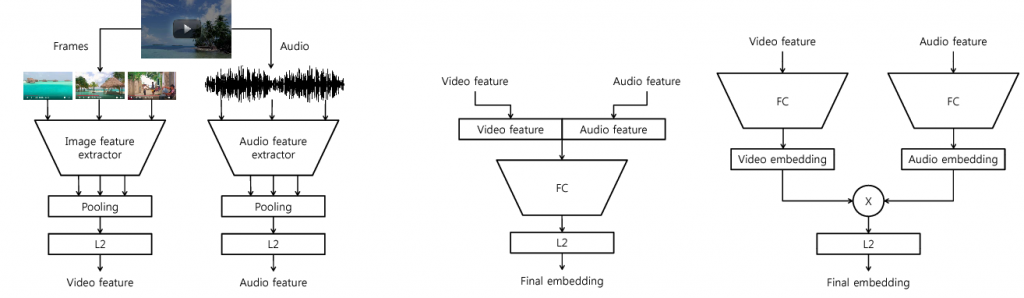
ⓒ Collaborative Deep Metric Learning for Video Understanding 논문
샴 네트워크에서도 특징 추출기(CNN)을 활용해 두 데이터와의 거리를 통해 같은 클래스인지 아닌지를 판단하는데 ’embedding’이라는 용어를 사용했습니다. 샴 네트워크는 클래스 종류가 많고, 특정 클래스에 대한 이미지 양이 적을 때 그 클래스를 구분해내기 위해 고안된 네트워크입니다.
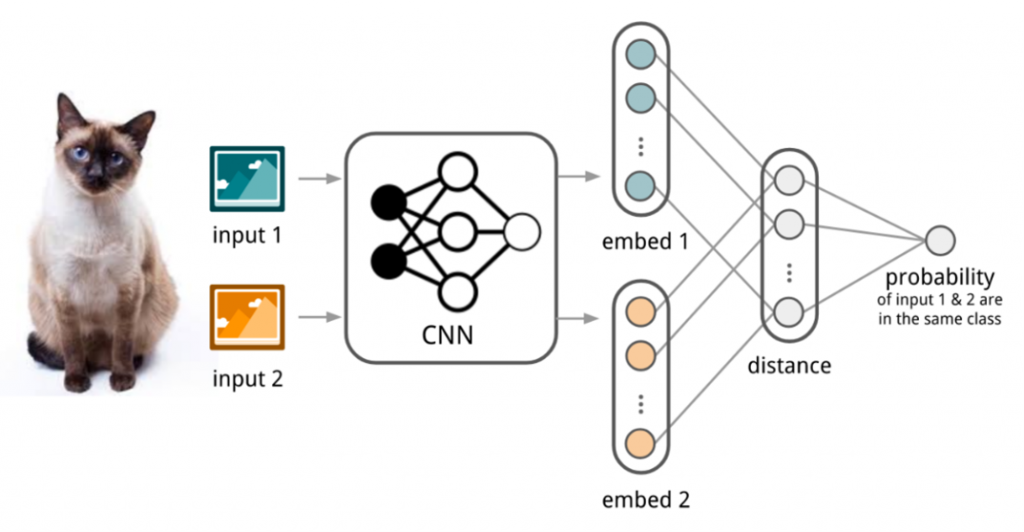
아이브이웍스의 영상 ’embedding’
아이브이웍스의 영상 임베딩은 어떨까요. 자사가 사용하는 데이터는 RHEED 영상입니다. RHEED 영상은 에피웨이퍼의 성장 과정을 MBE 장비를 통해 얻을 수 있습니다. 저희는 CNN이 결합된 알고리즘으로 RHEED의 패턴 변화를 효율적으로 임베딩했습니다. 또한 웨이퍼 품질 평가 지표를 예측하고자 할 때, 지표와 RHEED에서 밀접하게 관련 있는 정보를 자체 알고리즘으로 수치화시켰습니다. 그 결과 영상 딥러닝 알고리즘보다 영상 임베딩 알고리즘이 훨씬 더 우수한 성능을 보였습니다!
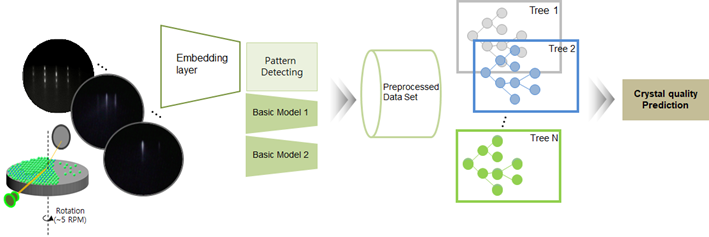
아이브이웍스의 모델은 영상을 임베딩한 결과만 사용하지는 않습니다. 아이브이웍스가 개발한 크리스탈 결정성 예측 모델은 Basic Model 들과 함께 결합하여 80% 이상의 성능을 이끌어냈습니다. 그리고 각각의 feature들은 설명력 있는 feature들이 되었습니다. 아이브이웍스 AI 팀은 느낀 점이 있습니다. 우수한 딥러닝 알고리즘만으로 해결할 수 있는 것은 현업에서 상당히 어려운 일이며, 그보다 중요한 것은 데이터를 이해하고 목적에 맞게 변환하여 머신러닝 모델을 접목하는 방법이 훨씬 좋은 해결책이 될 수도 있다는 점입니다.
하지만 아이브이웍스는 80%의 정확도에 머물러있지 않고 더욱더 성능을 높일 계획을 가지고 있습니다. 도메인 지식을 갖춘 자사의 우수한 반도체 소재 성장 전문가들과 인공지능 전문가들이 협력해 데이터를 한 차원 더 깊이 이해하고 그 아이디어를 통해 모델을 더욱더 탄탄하게 만들 예정입니다. 다음 칼럼에서는 아이브이웍스의 Basic model 들과 기존 모델에 어떻게 성능을 높일 수 있었는가에 대해 이야기하도록 하겠습니다.
Seul-Lam Kim l Artificial Intelligence team